Running complex inference on state-of-the-art AI models is now reduced to just three lines of code:
response = openai.Completion.create(
engine="gpt-4",
prompt="what is the meaning of life?"
)Nothing stops developers from exploring possibilities. All managed LLMs even offer similar abstractions (Claude, Cohere, and LLaMA to name a few). The question is: why haven't enterprises adopted these en mass?
We don't mean simple chatbots where the output can change by time of day. We're talking about deep integrations of LLMs into your applications.
After interviewing hundreds of engineering leaders spanning startups to enterprises, we've boiled down the patterns to three concerns:
- Accuracy: Synonymous with "hallucinations", it simply means the model's results aren't grounded in reality. This can be as insignificant as telling the wrong time, to as critical as telling the wrong bank balance. Tons of options can reduce these hallucinations. Developers can tune the model's hyperparameters, introduce Retrieval Augmented Generation (RAG) techniques and implement Reinforcement Learning with Human Feedback (RLHF).
- Latency: Calling some of the beefier LLMs, whether they be managed or self-hosted, introduces significant latency. This is often due to network egress/ingress, hardware resources, and simply the size of the models. We haven't however seen any managed models get round-trip latency below 800ms. For context, standard APIs are 50-300ms. ML engineers can always quantize the models, which has it's own tradeoffs.
- Cost: GPT-4's pricing structure is $0.03 / 1K input tokens and $0.06 / 1K output tokens. Using the tiktoken library, we calculated this article as containing
1548 tokens, which would cost $.05. This doesn't seem like much, but imagine creating 1000 iterations, after-all models are always evolving and inference is never one-and-done. Usage-based pricing such as charging per token has it's tradeoffs. We've seen teams use models such as LLaMA in their ETL pipelines, which gets expensive fast.
Other concerns such as privacy, learning-curve, explainability and maintainability are top of mind but fall below accuracy, latency and cost.
The core answer to all of these concerns is to create a Separation of Duties. Said differently, task-specific models working together to achieve a larger task. This can be referred to as model daisy chaining, ensemble learning or staged analysis.
Take a facial recognition example, expanded here
- Model One: Given a picture, generate bounding boxes of all the faces in the frame
- Model Two: Measure the features in the contents of each bounding box. For example, the distance between eyes, nose and mouth
- Model Three: Generate embeddings of each feature distances
To reduce errors and latency, each model is trained, deployed and optimized independently. Model one can have hyperparameters A & B for use case X, while Model two can have hyperparameters D & E for use case Y. Then combine each of these combinations within the context of the entire chain, it quickly becomes combinatorially explosive... 🤯
Prediction: To optimize for accuracy, latency and cost, engineers will increasingly combine models with data queries then glue them together with code.
NUX enables developers to safely experiment with the evolving state of data, models, and code in a familiar playground interface that, once "ready", maps to infrastructure as code that can be deployed anywhere. We handle handle the journey from prototype to production with ease 😎.
Explosion of Options
There's a myriad of models, data and code to choose from, which creates analysis paralysis for engineering orgs, reducing their "time to value". Skunkworks projects and hackathons can give developers the freedom to evaluate each of these for their use case.
Data
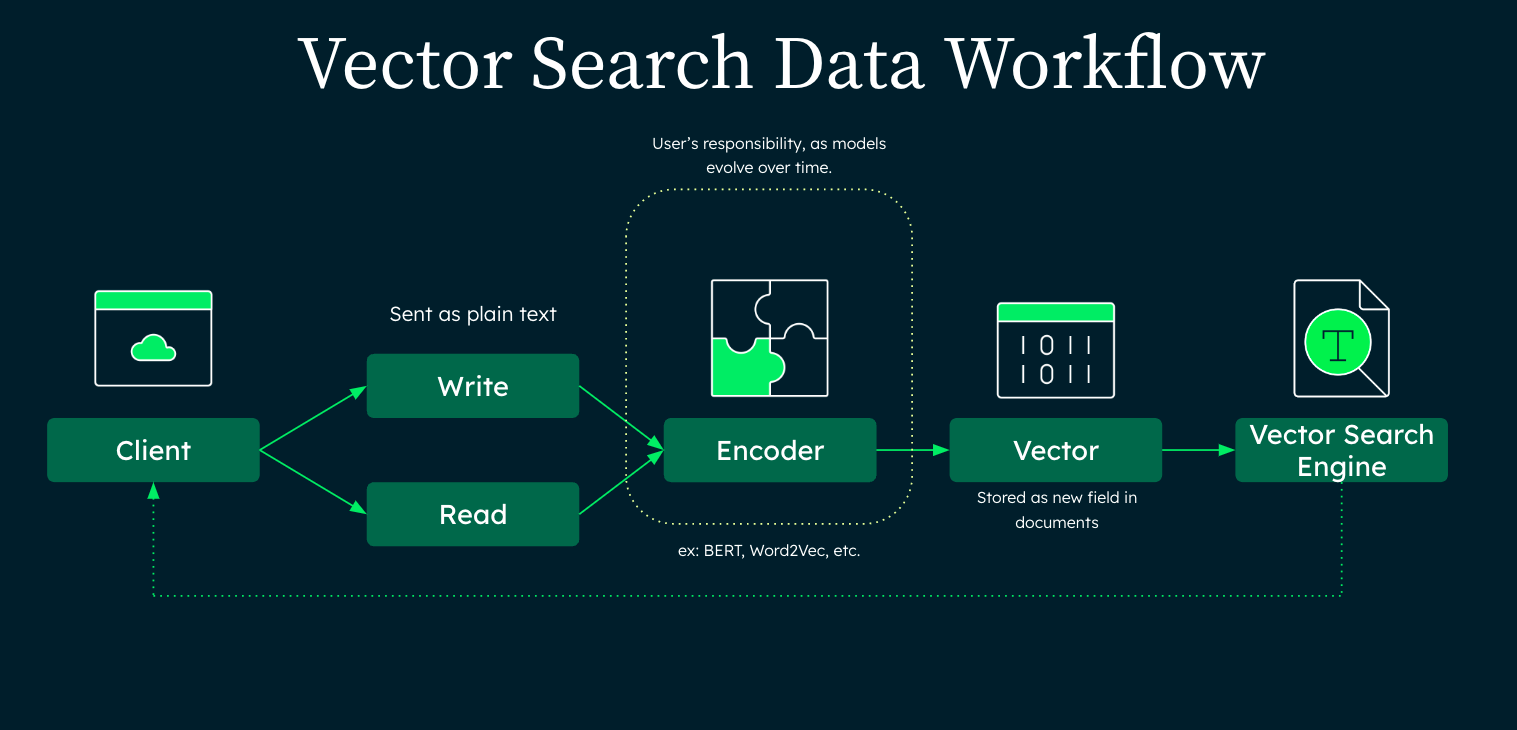
Vector databases, transactional databases, and text indexes often get paired with 3rd party APIs and all have their own re-ranking solutions. Different embedding models, similarity algorithms (cosine, euclidian, dotproduct), metadata filtering, and top_k all yield their own results
We maintain an open source vector database comparison/evaluation repo: http://vectorsearch.dev/
| Name | Open Source | Index Type |
|---|---|---|
| Pinecone | No | Vector |
| MongoDB | Yes | Hybrid (Dense, Sparse, NoSQL) |
| Weaviate | Yes | Hybrid (Dense and Sparse) |
| No | Vector | |
| Elastic | Yes | Hybrid (Dense and Sparse) |
| Algolia | No | Text |
| Vespa | Yes | Hybrid |
| Milvus | Yes | Vector |
| Redis | Yes | Transactional (Dense, Sparse and Key Value) |
| Qdrant | Yes | Vector |
| OpenSearch | Yes | Hybrid (Dense and Sparse) |
| LucidWorks | No | Text |
Models
Huggingface now has over 1 million models in their inference catalogue. There are over 20 managed LLMs that all have their own trade-offs. Different hyperparameter options (temperature, top_p, etc.) and baseline models (7b vs 30b parameters) all yield completely different results.
| Name | Open Source | Type |
|---|---|---|
| GPT-4 | No | Sentence Completion, Text Generation |
| LaMDA 2 | No | Conversational AI |
| Claude | No | Sentence Completion, Text Generation |
| Bard | No | Text Analysis, Generation |
| Cohere | No | Natural Language Understanding, Generation |
| LLaMA2 | Yes | Text and Code Generation |
Code
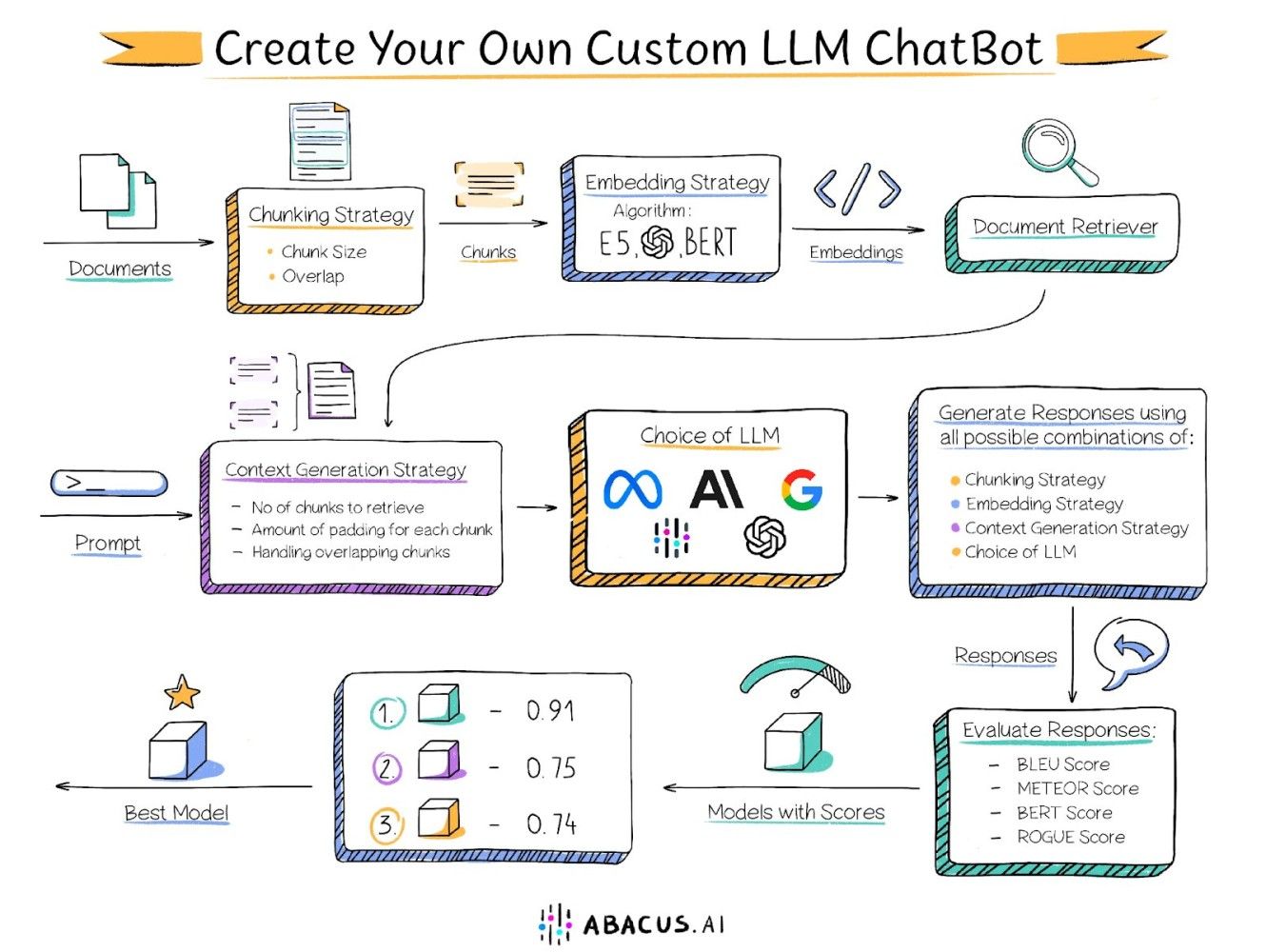
Pre-processing libraries can be overwhelming. Langchain for example has over 50 document loaders each with their own chunking parameters that vastly change the output quality of models.
| Name | Open Source | Type |
|---|---|---|
| LlamaIndex | Yes | Data Indexing |
| Langchain | Yes | Text Processing |
| Unstructured | Yes | Data Extraction |
| Haystack | Yes | Information Retrieval |
On the path to production, engineers must combine each of these primitives (ex: Pinecone, GPT-4 and Langchain) chain them together, and experiment with the parameters of each to see how they perform against acceptance criteria.
Rapid Prototyping
- Objectives: This involves conducting market research, talking to users, defining scope, and more.
- Consolidation: All technology options need to vetted against security and compliance concerns then be quickly accessible to developers. Ensuring solutions are "air-gapped" is often key. Middleware tooling can accelerate this.
- Learning Curves: Some tools such as Langchain are notoriously more challenging to work with than LlamaIndex, but expose more functionality. Workshops and documentation can accelerate this.
- Acceptance Criteria: It's helpful to define what the output of a happy-path pipeline is. This allows frameworks such as optimize to automate bruteforce hyperparameter optimization.
- Cost Optimizations: Develop a budget that accounts for tokens, compute and operational management. Sizing hardware and projecting spend can involve asking questions and defining assumptions.
Path to Production
- Independent Scaling: Scaling each block within the chain independently can reduce overall capex and increase performance. Every stage is deployed as a container with defined inputs, outputs and resources. Why should a tiny spellcheck model live on the same server as your beefy LLM? This also grants load balancing to distribute traffic and compute evenly.
- Inclusive Network: By having all the systems coupled within the same network, not only does it reduce privacy concerns it also drastically reduces latency. Do you trust these models with your code? How do you know it won't be used for other purposes?
- Hosting: GPUs, CPUs, RAM/Disk allocation and more are all the options to consider. Then figuring out hosting LLMs for inference, etc. and how this impacts cost structure.
- Monitoring: Track system performance, model accuracy, and user engagement.
- Error Handling: Alerting mechanisms to notify the team of errors or performance degradation.
- Integration: Creating a seamless API layer for integration and endpoints to keep the system up to date (webhooks/triggers and streaming pipelines)
Inference
If you want to call your LLMs and ML models, you need to host them for inference. Here are some options:
| Name | Open Source | Type |
|---|---|---|
| SageMaker | No | ML Model Building and Deployment |
| Nvidia Triton | Yes | AI Model Serving Framework |
| Ray | Yes | Distributed Computing for AI |
| HF Inference | No | Model Hosting and Inference |
| ClearML | Yes | ML Ops and Versioning |
| BentoML | Yes | Model Serving and Deployment |
| RunPod | No | GPU Cloud for AI and ML |
| BaseTen | No | ML Model Deployment |
| Modal | No | ML Model Development and Deployment |
| Banana | No | ML Model Monitoring |
| Cerebrium | No | AI-based Analysis and Prediction |
| Lepton | Yes | Distributed Deep Learning |
| Fireworks | No | ML Model Scaling and Management |
| Octoml | No | ML Model Optimization and Deployment |
Evolving
- Feedback Loops: Continuously monitor and adjust the model parameters automate acceptance criteria testing.
- Reinforcement Learning: Collect user feedback and use it to inform model retraining and updates. Then schedule batch updates.
Is this exciting? Overwhelming? NUX standards for New User Experience, and we're building for this transition of Playground to Production with two offerings:
- Playground: Consolidated, Jupyter-like familiar workbook interface to combine organization-vetted models, data connections, and coding packages.
- Production: Export your workbook into Infrastructure as Code, which translates into a container orchestration system that can be deployed anywhere. On-premise or in your cloud's VPC.