Chat opened up the floodgates for AI, but it's far from the future. The future is task-specific, interdependent models. Small context windows, reliably accurate, cheap and fast.
The AI Bifurcation
- On one hand you have LLMs context windows expanding to the point where they'll swallow up your Snowflake Data Warehouse. This is the progression, as evident by Google's Gemini 1 million context window LLM.
- On the other you have smaller, task-specific models that are fine-tuned to perform fast, accurate, and cheap on a specific domain.
Both of these directions have purpose. We've seen chat and Q&A use cases take the world by storm, and that will only be compounded by larger context windows.
Customer support teams can feed an entire user's interaction history into the chat window so they never have to repeat information again. Massive context windows are also useful for Agentic workflows, where autonomous agents act on behalf of a user. These agents need as much context as possible to make relevant decisions, intelligently.
Agents and Q&A chat are played out, and many people are solving these problems well, so we won't discuss this.
However, for the task-specific models we're seeing an emergence of use cases that span analytics, workflow automation, and microservices.
Many amazing companies are attacking analytics as well as workflow automation, but I have yet to see a company solely focused on microservices architecture.
The RAG Microservices Stack
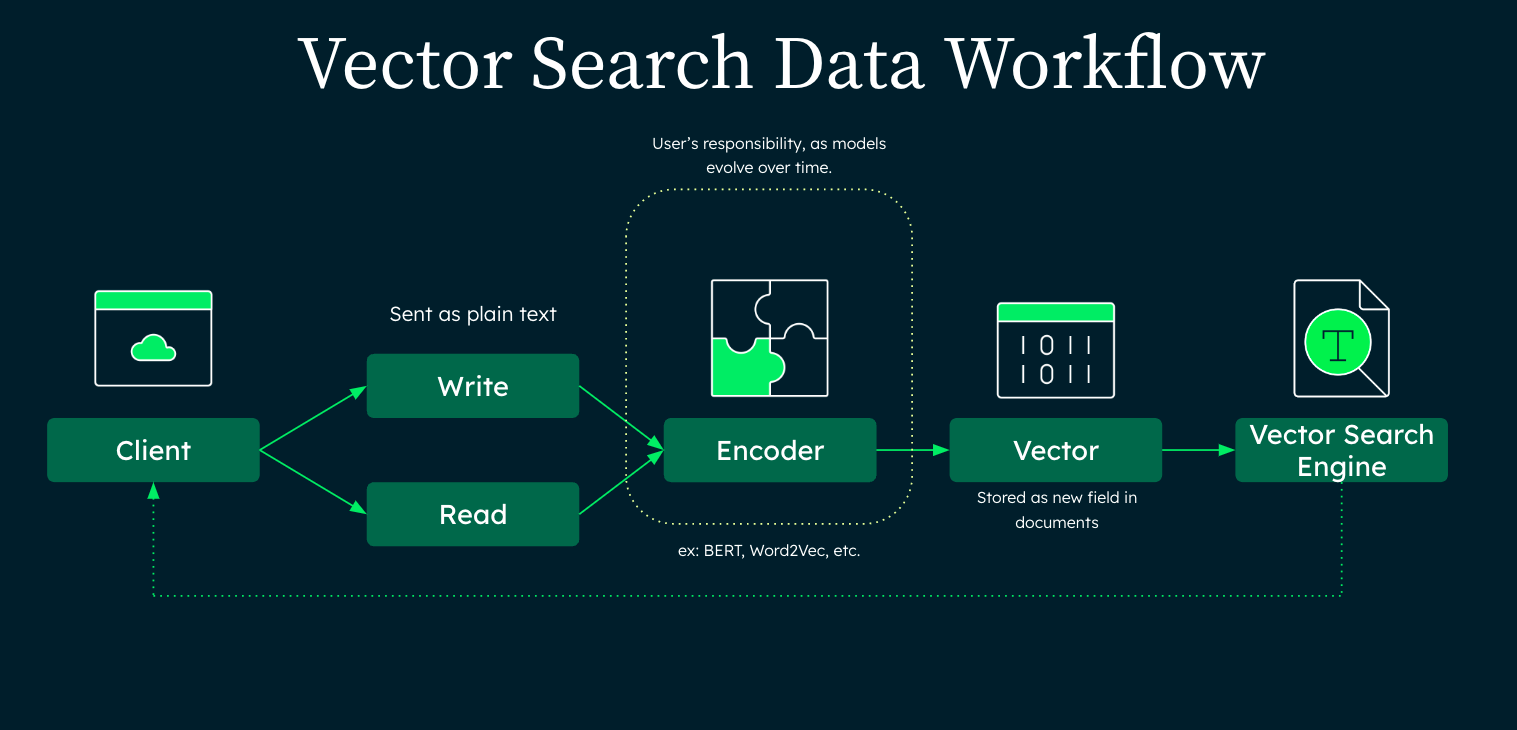
The stack consists of indexers and retrievers. Both are capable of reusing the same core components: Query + LLM but do so in different ways.
Core Technologies Required
Hybrid Database Systems: Combining vector databases for efficient similarity search (using embeddings), TF-IDF for relevance scoring, and traditional databases for structured query handling. This ensures flexible, fast retrieval across different data types and use cases.
Schema Sampling & Embedding Models: Techniques for efficiently understanding and sampling from large data schemas, and using embedding models to convert textual or structured data into a format suitable for machine learning models.
Model Hosting, Fine-Tuning, and Hyperparameter Optimization: Services that allow for the hosting of large language models (LLMs), providing the capabilities to fine-tune these models on domain-specific data and optimize their performance through hyperparameter adjustments.
Human in the Loop (HITL) Feedback/RLHF (Reinforcement Learning from Human Feedback): Mechanisms for incorporating human feedback into the training loop, improving model accuracy and reliability over time.
Guardrails Services: Implementations to ensure LLMs operate within predefined ethical and operational boundaries, preventing misuse and ensuring compliance with regulations and guidelines.
Swap-Out Mechanism for Services: A system design that allows for the easy replacement or updating of microservices without disrupting the overall architecture.
Standard SLDC Practices
- Version Control: Use tools like Git for managing code changes and collaboration.
- CI/CD: Implement continuous integration and continuous deployment pipelines to automate testing and deployment processes.
- Load Testing: Regularly test the system under heavy loads to ensure scalability and performance.
- Canary Releases: Gradually roll out changes to a small subset of users before a full rollout.
- Monitoring & Error Handling: Deploy monitoring solutions to track the health of the system and implement robust error handling to quickly address issues.
Addressing Common Frustrations
Engineers often face challenges with libraries like LangChain and LlamaIndex, particularly the "80% problem," where a library almost meets requirements but falls short in certain areas. Overcoming this involves:
- Custom Development: Extending libraries with custom code to fill in the gaps.
- Community Engagement: Contributing to or engaging with the community to enhance library features.
- Modular Architecture: Designing systems to be modular, allowing for easy swapping of components as better solutions become available.
Ensuring Low Latency, Cost-Efficiency, and Accuracy
- Efficient Indexing and Caching: Implementing smart indexing strategies and caching frequent queries can dramatically reduce latency.
- Service Optimization: Regularly reviewing and optimizing service configurations and resources to balance cost and performance.
- Quality Assurance: Implementing rigorous testing and validation processes to ensure the accuracy and consistency of responses.
Companies/Products/APIs
- Hybrid Databases: MongoDB Atlas Search, Elasticsearch, Faiss for vector search.
- Embedding Models/Hosting: Hugging Face, Google AI Platform, AWS SageMaker.
- Guardrails Services: OpenAI (for GPT models), AWS Comprehend for natural language processing guardrails.
- SLDC Tools: Git for version control, Jenkins or GitHub Actions for CI/CD, Prometheus and Grafana for monitoring.